
When you build something new and are chasing product market fit, time to market matters. You value simplicity and fast, iterative feedback. Scale doesn’t matter; you use the tools with which the team is most familiar, and you definitely don’t go all-in on microservices¹ 😉. Instead, you aim for a system that is practical, flexible, and lets you quickly explore the problem space to maximize learning – you need a mountain bike.

But every 10x in scale requires you to adapt and rethink past decisions. The mountain bike feels fine for the first couple years, but eventually you struggle to keep up with the growth of the business – you need to move faster and support more customers and data than you can with a manual approach. Processes need to be automated, infrastructure needs to be upgraded, and systems need to be rearchitected, but you still need to be able to navigate uncharted territory quickly. You need a dirt bike.

This is exactly where we were at Stellar towards the end of 2021. We had a promising business model that provided us with significant runway, and great traction with our customers. But in the engineering org, we were beginning to feel underwater as we faced an increasing set of scaling problems. Nearly every successful organization outgrows the first iteration of its infrastructure, and we’re no exception – what differentiates engineering cultures is how they approach that problem.
Investing in technical infrastructure & scale is expensive and difficult. You need organizational buy-in, a sound technical plan, and principles that help you “right size” your next iteration. You need to understand and justify why you’re building a dirt bike and not a Ducati, because it’s not always obvious where to draw the line.

At Stellar, we use OKRs, or Objectives and Key Results, a model originally popularized by Andrew Grove (former CEO of Intel), to align the company on both critical high-level goals, and how we’ll measure our progress against them. We decided that for 2022, we’d set a company-level OKR that demanded we invest in scaling our infrastructure, and then prove to ourselves that our system can support 10x the patient volume we had at the end of 2021.
This was a very intentional push to break out of a shorter term mindset, to think with a multi-year time horizon, and at a scale that was an order of magnitude beyond what we had seen to date. For our engineering org, this was both exciting and challenging – we applied a first-principles approach to the problem, estimated what 10x scale meant for our system, ensured that our ideas would keep in mind domain-specific constraints like HIPAA compliance², and then we worked from the bottom up to identify what would break first.
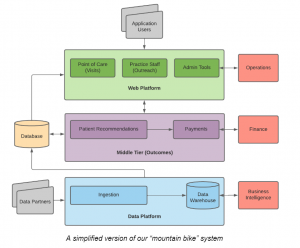
In our web platform, we highlighted limitations with Django server-side templates when building our ideal interactive, performant user experience, and we found that our complex queries (particularly those with aggregations) run directly against a shared PostgreSQL database weren’t scaling.
In our middle tier, where we generate patient care recommendations, we felt good about our ability to scale reads, but writes had become a bottleneck. We were also lacking a clear interface between frontend and backend teams, and that led to too much tight coupling. Scaling issues that are organizational in nature can be just as limiting as those that are technical.
In our data platform, we flagged that our home grown system of cron-triggered ETLs wouldn’t be able to keep up with the anticipated patient volume. These systems used the same shared PostgreSQL database, which meant ETLs could impact user traffic, and we knew we wanted to both eliminate this dependency, as well as modernize our approach to processing data.
These bottlenecks then led to proposals for a number of technical initiatives – some were small and required a few weeks of work, whereas others called for significant changes, like switching to React on the client, or rebuilding our data pipelines from scratch using the latest AWS technology (e.g., Glue & DataBrew). Ultimately, we synthesized these ideas into a new vision for our technical infrastructure, and laid out a year long technical roadmap that we socialized with the engineering org, product, and our leadership team.
So where are we now?
We’re currently building high-impact projects and infrastructure that we believe will transform how our business operates. We’re also thinking through how we will measure the scaling improvements we’re making and be confident in our ability to support 10x the patient lives.
This has been a really positive exercise, and we benefited tremendously from the company-level alignment in this year’s technical scaling investment. It’s not often that a smaller company has the maturity, focus, and financial runway to support this kind of long-term thinking, but it’s a hallmark of how Stellar operates. We hire intelligent, engaged, high performers who think like owners, and then we empower them to shape the vision and trajectory of our company.
In a future post, we’ll dive deeper into at least one of our big technical investments – we’ll talk more about its specific challenges, and where it ended up. Stay tuned and remember to choose the right “bike” for your own stage of growth!

¹Microservices (and service-oriented architectures more generally) aren’t bad, per se, but monoliths are perfectly fine (and simpler!) for much longer than most realize.
²HIPAA is a US standard for health data privacy and security. Operating in the health space means we need to account for this and other regulatory standards while also trying to meet our various business and technical goals!